一句话读论文:Panoptic Neural Fields(CVPR2022)
一句话读论文:Panoptic Neural Fields(CVPR 2022)
论文标题:Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation(CVPR 2022)
论文地址:https://arxiv.org/abs/2205.04334
作者单位:Google Research, Georgia Tech, Simon Fraser University, Stanford University
代码地址:暂无
一句话读论文:"We present Panoptic Neural Fields(PMF), and object-aware neural scene representation that decomposes a scene into a set of objects(things) and background(stuff)."
To Xicc,
封面图感谢Xicc的无私分享!!!此生无悔入四月。
网络框架:
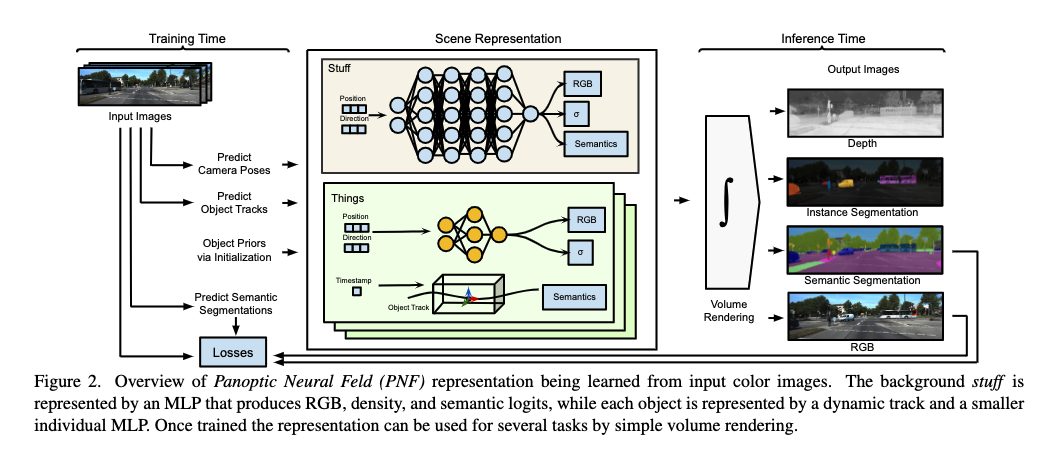

核心内容:
大佬们请收下我的膝盖!!!
Motivation:
把多用于室内场景的Nerf首次应用到室外自动驾驶场景中
Nerf原先多用于View Synthesis ,图形学渲染,重建。本篇工作窥得大佬们的野心:想在室外自动驾驶场景中,把分类、语义分割、目标检测、目标追踪、全景分割、三维重建、深度估计、场景编辑与生成等一系列任务全部做到SOTA指标,从而让Nerf一统2D-3D视觉任务的天下。虽然本篇工作是初步的尝试,但是开辟了一个新的研究领域。
相比于之前在Nerf基础上各种incremental类型的工作,本篇工作提出一种室外场景通用类型的Nerf框架。主要分为stuff类别和thing类别,除了分别学习传统Nerf模型所需要的color, pose,density 等信息,还加入语义信息,最后将stuff类别与thing类别共同合成panoptic radiance field,用于各类下游任务。
在已有的语义分支+Nerf, Dynamics+Nerf等各种变体基础上,取消了共享的MLP网络,而是为每一种类别的物体instance设计小的MLP网络;此外在初始化上引入类别的先验信息,设计了category-specific meta-learned initialization
本文的方法:在原版Nerf基础上,做如下变化
Things类别:
- 首先用RGB-only 3D Object Detector& Tracker 得到Bounding box
track
(由一系列仿射变换矩阵组成)和语义类别 . - 对每个物体实例,用标准的Nerf网络提取特征,该网络是由time-invariant MLP组成(不是随时间变化而变化的RNN时序网络),得到包括color, pose, density等参数信息
- 损失函数共同优化Nerf网络和
- 首先用RGB-only 3D Object Detector& Tracker 得到Bounding box
track
Stuff 类别:
- 用单一的Nerf网络提取Stuff类别,此外还有网络分支学习每个Stuff pixel的语义类别
Panoptic-Radiance Field
对color,densiy等通道采取如下融合方式
Render Panoptic-Radiance Fields
Nerf中权重先验的获取
- Bias initalization(设置stuff MLP的bias为-5,thing
MLP的bias为0.1,因为真实室外场景中stuff volume大多数是空的,而thing
volume大多数非空) 和 Meta-learn的方式(
FedAvg算法)
- Bias initalization(设置stuff MLP的bias为-5,thing
MLP的bias为0.1,因为真实室外场景中stuff volume大多数是空的,而thing
volume大多数非空) 和 Meta-learn的方式(
贡献点/创新性:
- 见Motivation的第1-3条
实验结果:


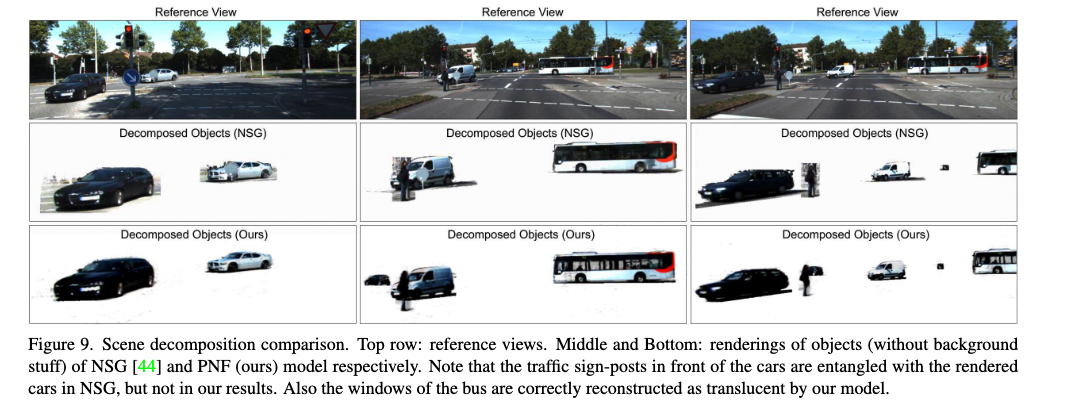
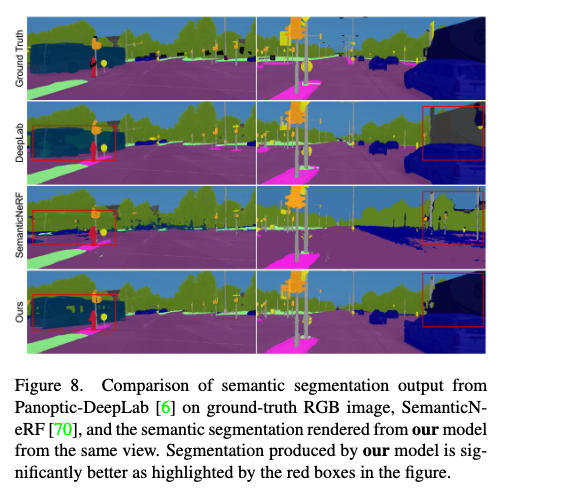

Related Work(可选, 后续再补充):
- Nerfs
- Nerfs with Semantics
- Nerfs with dynamics
- Nerfs with object decompositions
- Conditional NeRFs
- MVS
- SLAM
你认为优点/不足/可以拓展改进的地方(可选):
优点:
- 太多了吐槽不完
缺点:
- 虽然很大一统,但是整个框架挺复杂,目前只能在离线的训练和推理,不太容易直接应用在实时场景下。
其他笔记:
- CVer 计算机视觉:https://zhuanlan.zhihu.com/p/513499887