课程笔记:强化学习(2)——Bellman方程的动态规划求解
课程笔记:强化学习(2)——Bellman方程的动态规划求解
动态规划
本节只是非常粗略的把动态规划的要点总结一下,是课堂笔记纲要,并非详细讲解。先占个坑,以后有空再补
动态规划需要满足的条件:
- 最优子结构(Optimal substructure):
原问题的最优解一定也是子问题的最优解。例如,一个输入长度为N的序列的某个Scheduling问题(记为T(1,N) ) 的最优解,拆分后一定也是其子问题T(1,N/2-1), T(N/2, N)的最优解。
问题的最优解可以通过某种形式组合和计算,得到原问题的最优解
- 重叠子问题
- 子问题与原问题有同样的format和structure
- 无后效性
- 计算原问题最优解时,不会对子问题最优解产生影响。
马尔科夫链和马尔科夫决策过程满足上述三个条件的,因为:
- Bellman方程将原问题递归的分解为规模更小的子问题
- 子问题拥有同样的format和structure
- Que? 有疑问,虽然马尔科夫过程强调每个state只与上一个state有关,与其他state无关(
Dynamic Planning in MDP:
- For prediction(Policy Evaluation):
Input: MDP
和策略 or MRP (没有显示的策略表示,是Implicit Policy) Output: value function 对Policy Evaluation的理解:给定一个策略,通过贝尔曼方程迭代求出所有状态的价值 ii.For control:
Input: MDP
Output: 最优价值函数
和最优策略 Bellman方程:
(State-) Value Function:
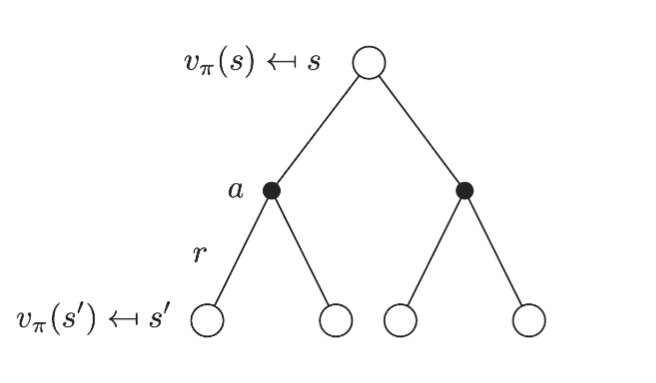
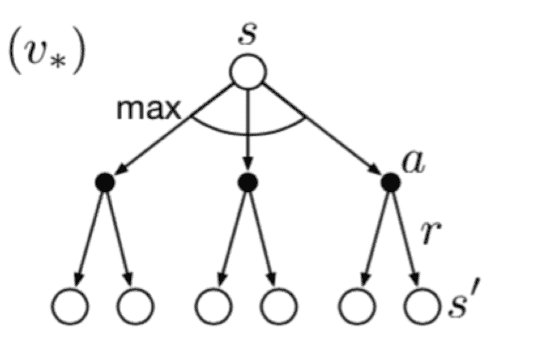
求Optimal
Action Function:
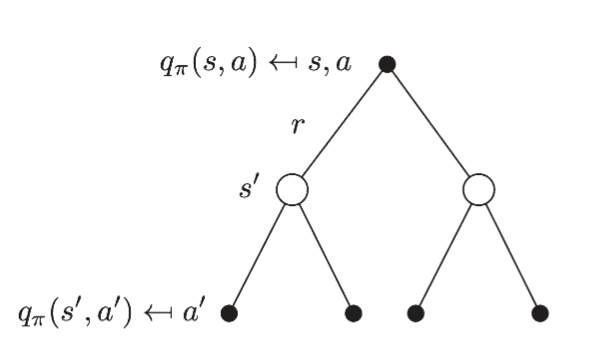
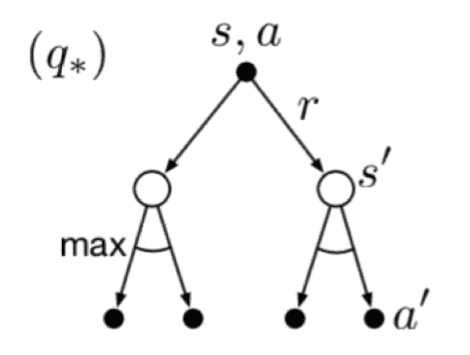
Policy Evaluation

给定一个policy
Policy Iteration

这个是通过贪心的策略来迭代得到最好的policy。基本思想是
Value Iteration

这个的特点是没有给定任何显示的(explicit)策略
与Policy Evaluation 和Policy Iteration 不同,
前两者都出现了
等迭代结束,value全部求出来后,最后一遍求解
Summary
