论文精读笔记:Luna--Linear Unified Nested Attention
论文精读笔记:(Neural IPS在投,2021) Luna--Linear Unified Nested Attention
Abstract
传统Transformer中的注意力机制计算量是平方级别的。本文提出了Luna,Linear Unified Nested Attention 的方法,通过增加一个额外的固定长度的序列作为输入和输出,把平方级别的注意力计算拆分成两个线性时间的计算步骤来做近似,并且该固定长度的序列可以存储足够的上下文相关信息(Contexual Infomation)。
Motivation
- 想提出一个简单有效减低计算复杂度的方法
- 传统的注意力机制的计算和存储都是\(O(n^2)\)的(\(n\)表示序列的长度),但是对于长序列输入,序列间相关性往往是稀疏的(不是完全图)
- 已有的改进方法: 1)利用稀疏性约束(Sparse Attention),如local attention[1], strided[2][3], Hierarchical Global Attention[4],attention with learnable patterns[5] 2)利用注意力矩阵的低秩性,如Linformer[6] 3)kernel 方法,如Linear Transformer[7], Performer[8] , Random Feature Attention[9]
- 本文所提出的引入额外固定长度序列的方法简洁优美,且能有效将计算复杂度降低到线性级别。
Theorem&Model

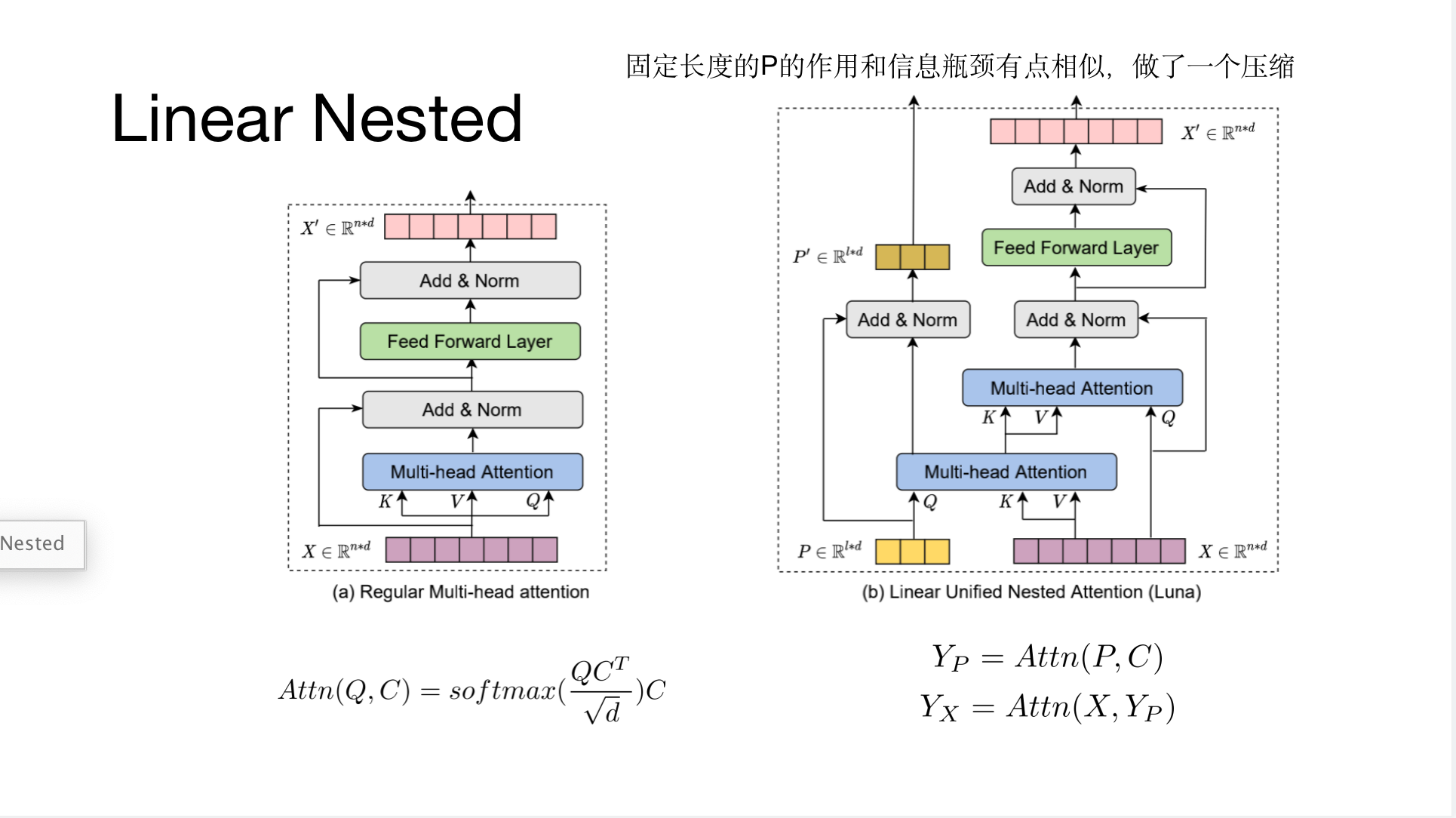
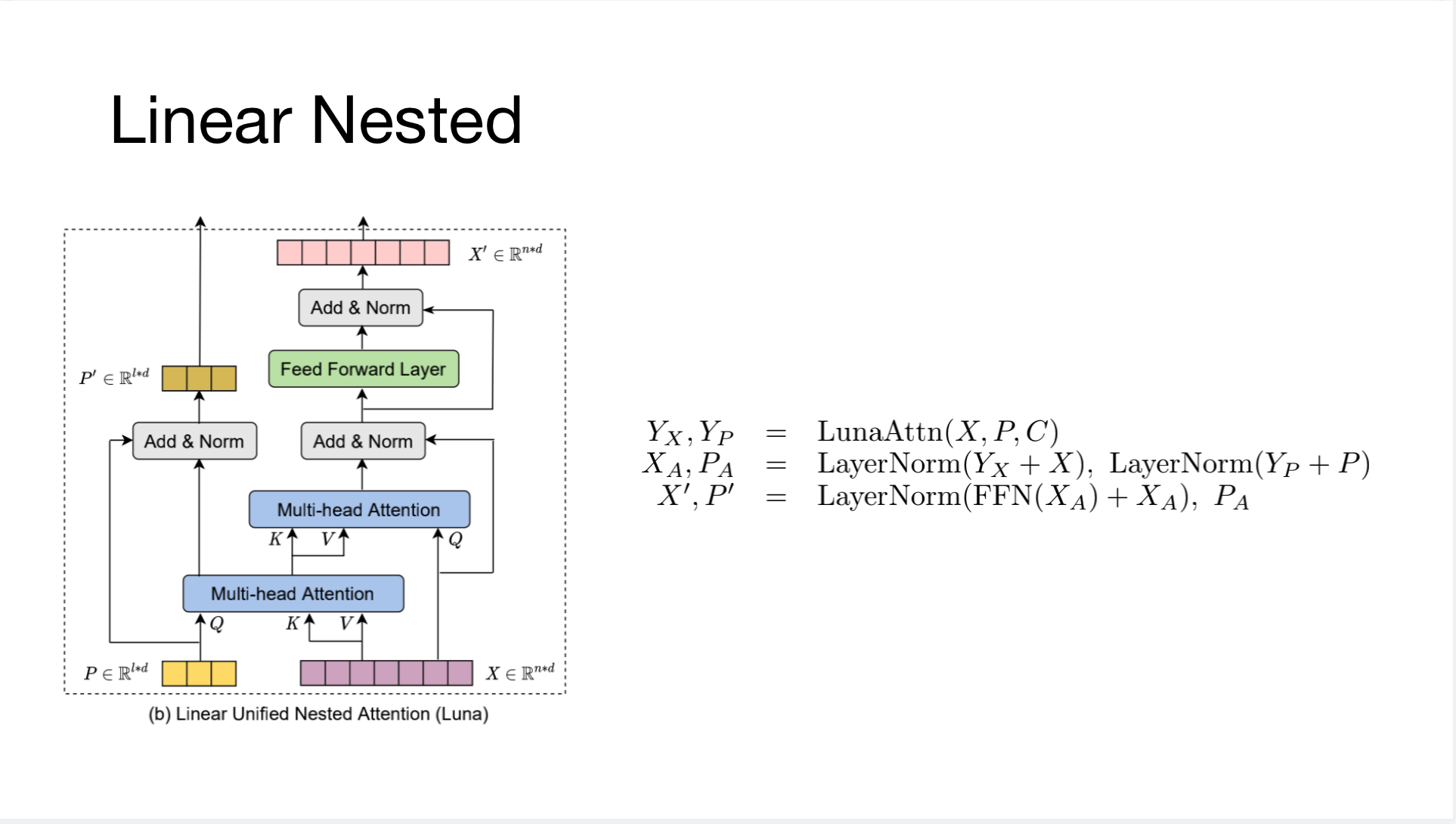
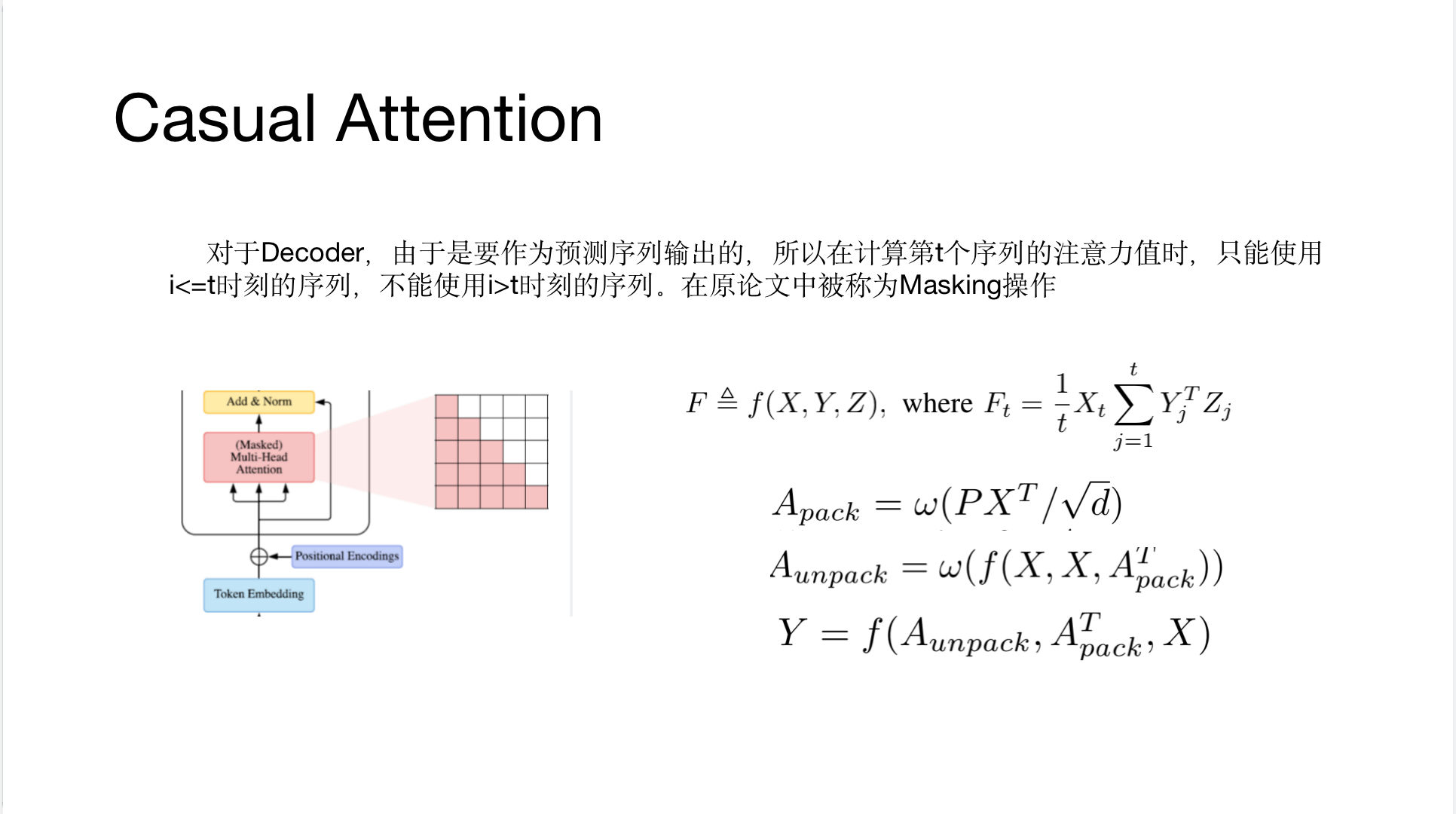
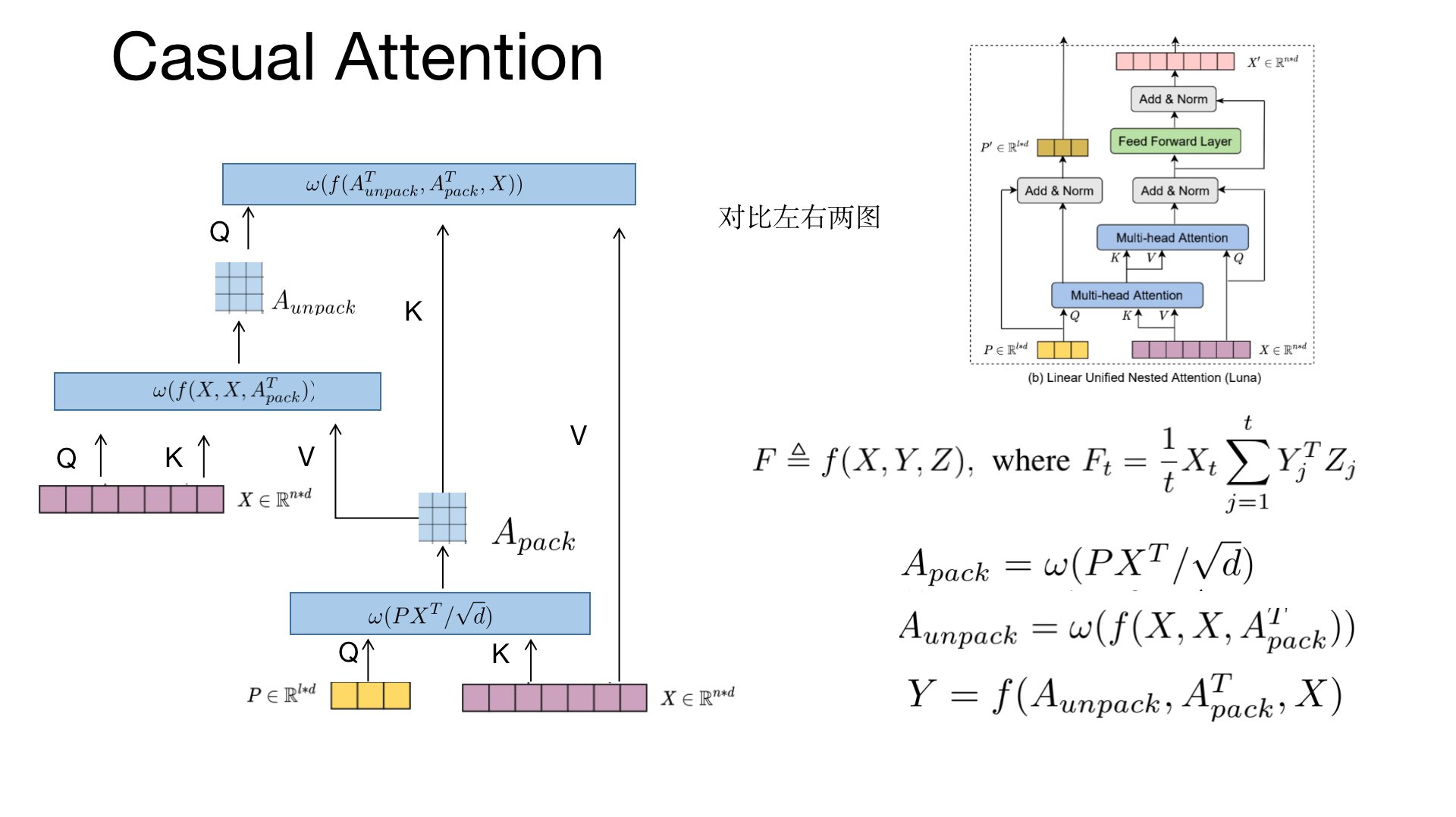
Contribution(Innovation)
Under review,暂不分析innovation如何。
Evaluation
暂略,待后续自己实验后分析。
其他
不过,本篇的idea和几乎同一时间(2021.06)放到Archiv上的External Attention using Two Linear Layers for Visual Tasks[10] 有同工异曲之处,详细可参考知乎介绍。
参考文献
- Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, andDustin Tran. Image transformer. In International Conference on Machine Learning, pages 4055–4064. PMLR, 2018. ↩︎
- Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019. ↩︎
- Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020. ↩︎
- Guo, Q., Qiu, X., Liu, P., Shao, Y., Xue, X., & Zhang, Z. (2019). Star-transformer. arXiv preprint arXiv:1902.09113. ↩︎
- Aurko Roy, Mohammad Saffar, Ashish Vaswani, and David Grangier. Effificient content-based sparse attention with routing transformers. Transactions of the Association for Computational Linguistics,9:53–68, 2021. ↩︎
- Wang, S., Li, B., Khabsa, M., Fang, H., & Ma, H. L. (2020). Self-attention with linear complexity. arXiv preprint arXiv:2006.04768. ↩︎
- Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. In International Conference on Machine Learning, pages 5156–5165. PMLR, 2020. ↩︎
- Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers. arXiv preprint arXiv:2009.14794, 2020. ↩︎
- Hao Peng, Nikolaos Pappas, Dani Yogatama, Roy Schwartz, Noah Smith, and Lingpeng Kong. Random feature attention. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=QtTKTdVrFBB. ↩︎
- M. H., Liu, Z. N., Mu, T. J., & Hu, S. M. (2021). Beyond self-attention: External attention using two linear layers for visual tasks. arXiv preprint arXiv:2105.02358.URL https://arxiv.org/abs/2105.02358 ↩︎
论文精读笔记:Luna--Linear Unified Nested Attention
https://oier99.cn/posts/45554f7f/