课程笔记:统计学习理论与方法(ELS_Chap7)
课程笔记:统计学习理论与方法(ELS_Chap7)
📚书籍:《Elements of Statistical Learning》Chap 7
两个概念
- 模型选择(Model Selection): 模型由参数控制的,模型选择既包括模型类型选择,也包括参数的控制。后面讲贝叶斯信息准则时(BIC)会讲到。
- 模型评估(Model Assessment): 给定一个模型,评估其训练误差(In-sample Error),测试误差(Extra-sample Error),泛化误差(Generalization Error)。评估训练误差与测试误差之间的差距Bound.
两者都是侧重对模型的泛化误差进行评估,而非模型的训练误差。泛化误差是整个统计学习中最核心的关注问题。
训练误差与泛化误差
训练误差:
- 均方误差
- 对数极大似然函数【用于多分类】(严格来说这不算损失函数,但是极大似然最大等价于加符号最小,所以可以写成相同形式):
.其中 相当于真实标签(Ground Truth). - 对数极大似然的特殊情况【0-1分类】:
📢注意,我们算误差时的Ground Truth(GT)
Bias-variance 分解
假设:
考察在
关于期望与方差的常用性质,请参见这篇👉博客。
KNN的例子
KNN的模型是
线性回归的例子
对于线性回归函数
故
训练误差:
这部分的推导需要用到矩阵的迹的性质:
乐观度
乐观度(Optimisim)的概念主要是为了比较模型训练误差与泛化误差之间的差距,或者如何用训练误差去估计泛化误差。
直接计算训练误差和泛化误差的差有困难,因为模型输入
结论
若
有效参数量
有效参数数量(Effective Number of Parameters):
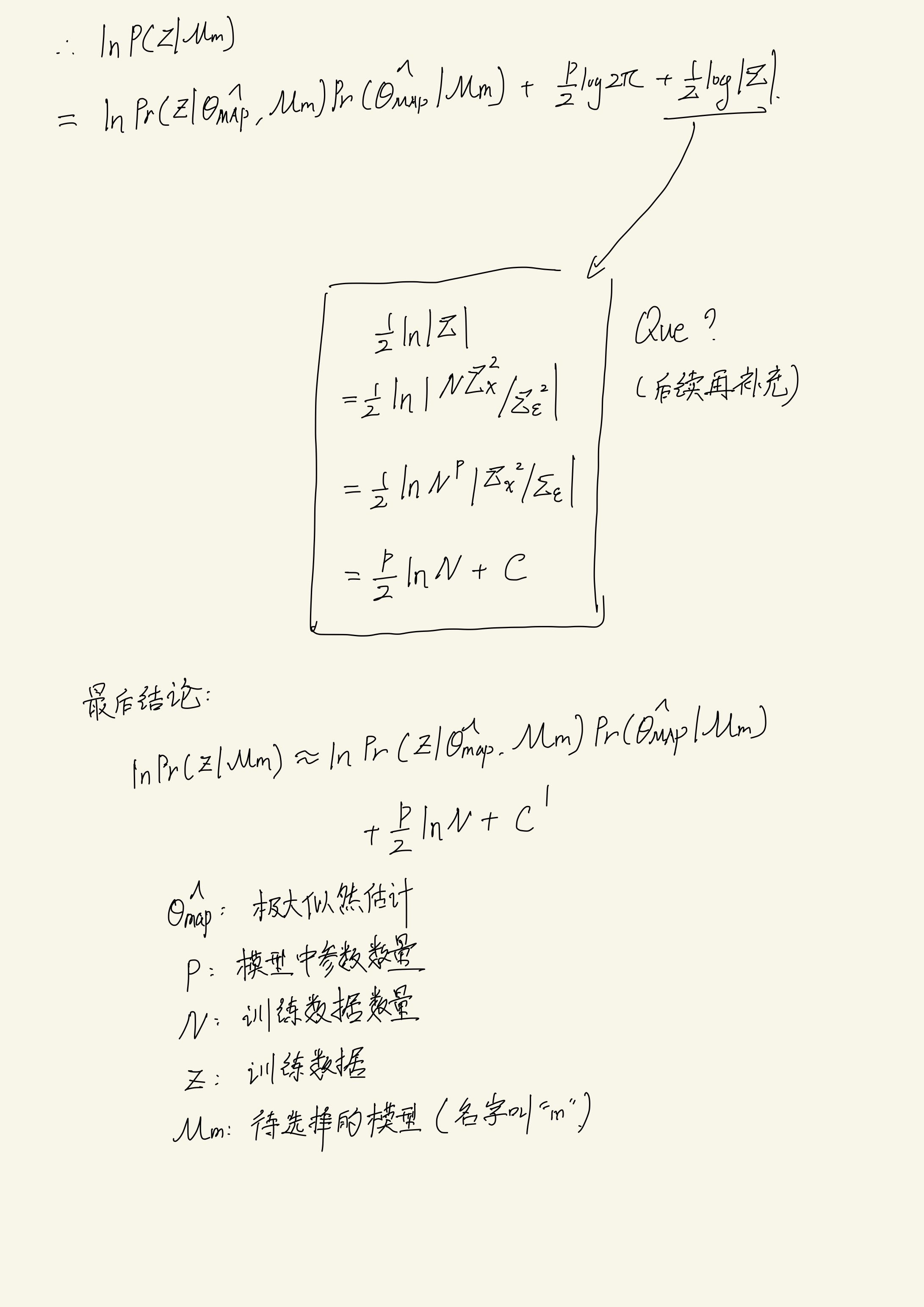
贝叶斯信息量(BIC)
题外话:前面的部分主要讲述的模型评价(Model Assesment)部分,贝叶斯信息量主要讲述的是模型选择的部分
BIC for 极大似然回归