课程笔记:统计学习理论与方法(ELS_Chap2)
课程笔记:统计学习理论与方法(ELS_Chap2)
📚书籍:《Elements of Statistical Learning》Chap 2
符号约定
| 输入变量(Input Variable) | |
|---|---|
| (随机)变量 |
|
| 模型输出 | Quantative Outputs: |
| 矩阵 | 大写加粗正体 |
| 向量 | 约定:普通的 |
统计学习的重要原则
Statistical Learning的目标是为了最好的泛化性能(Best Generalization Property)而不是最小的训练误差(Minimum Training Error)
线性回归
- 设输入是一个列向量
, 其每个维度分量下标是 写成矩阵形式,其中
线性回归的误差函数衡量方式——最小二乘
从最小化误差函数的方式,对
求导,得: 思考一下两种数据分布情况对线性回归模型影响:
- 训练数据中的每一类都是服从高斯分布,而且每一类的方差一样但是均值不同。
- 某一类的训练数据是由多个高斯分布合成的,可能高斯分布的方差和均值都不太一样,
对于第1种情况线性回归是比较optimal的,但是对于第二种效果比较差。
而K近邻算法对于第2中情况相对会更suitable.
(先占坑,后续补上解释)
如下图所示,先从
和 中分别随机采样10个sample(共计20个),前十个作为类别1的均值,后十个作为类别2的均值。然后每个类中各生成100个sample,每个sample都是从 采样,而每次 是从该类中的10个中等概率( )抽样得到。 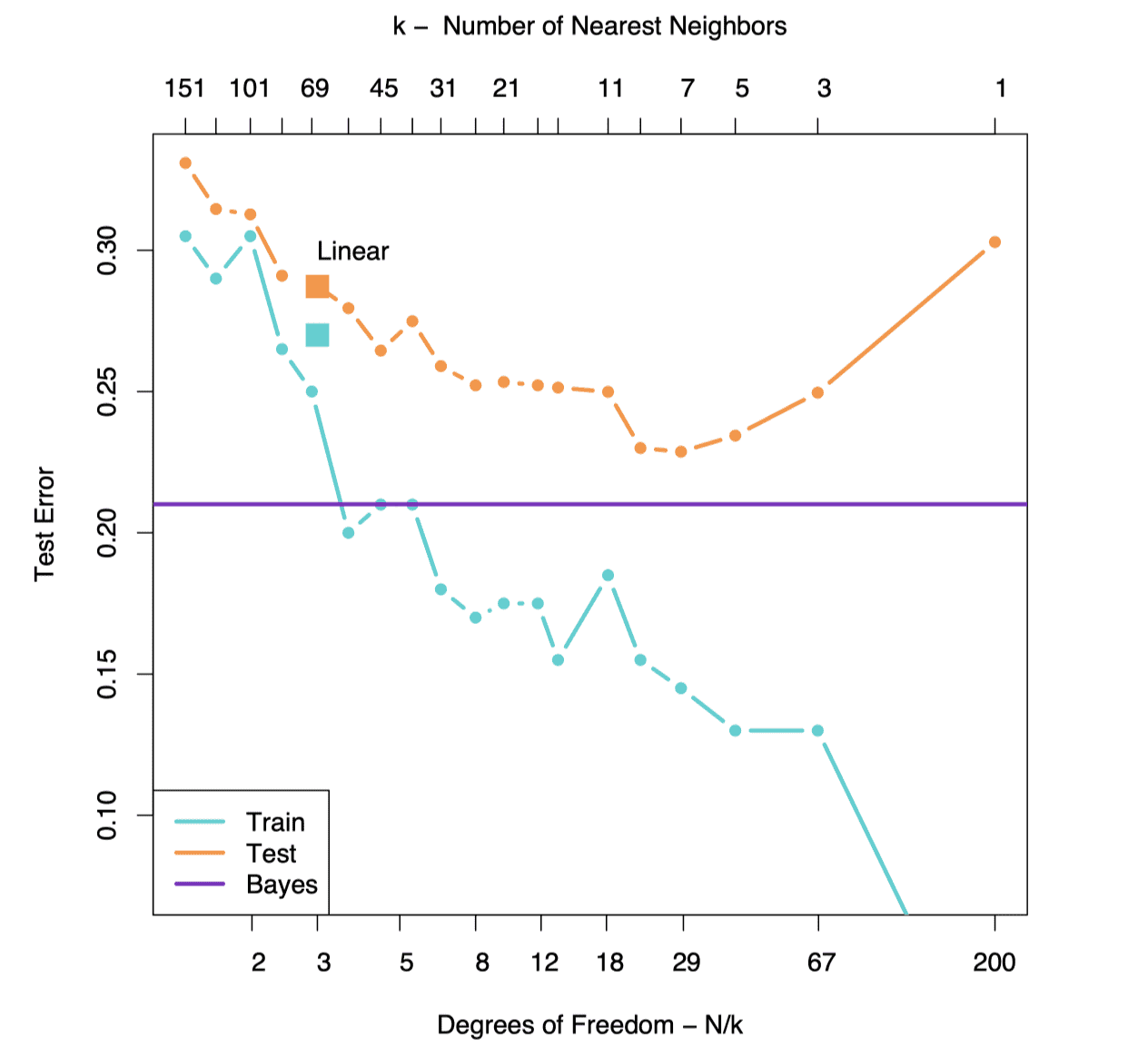
圆点连线代表的K近邻的Error曲线,两个方块代表三元线性回归的Error值。可以看到:
- 随着
值变小,K近邻模型自由度 在变大,模型复杂度在上升。模型逐渐由欠拟合转变为过拟合。后面也会讲解 - 可以看到在这种多高斯分布混合采样得到的数据集中,K近邻最好的Error要比线性回归好。
K近邻
几何意义:
在特征空间中,对每个训练实例点
,距离该点比其他点更近的所有点组成一个区域,叫做单元(Cell).每个训练实例点都拥有一个单元,所有训练实例点的单元对特征空间构成一个划分。 [1] 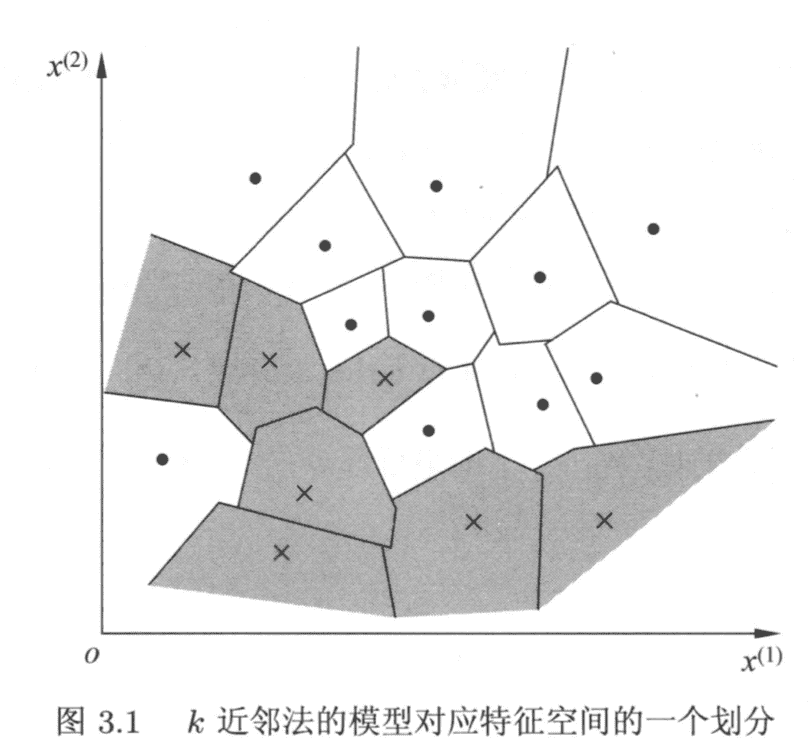
具体内容参见李航《统计学习方法》Chap3 课程笔记(先占坑,后面补上笔记后建立链接🔗)
统计决策理论(Statistical Decision Theory)
根据模型选择(Model
Selection)的理论,通过最小化期望预测误差(Expected
Prediction Error, EPE)来确定模型中的参数选择,从而确定模型。
对于回归问题的EPE
对于回归问题(不仅仅是线性回归),大多采用最小均方误差的方法计算误差:
含义解释:
理论上期望预测误差最小的回归函数模型,在最小二乘误差意义下,每个训练数据当
注意,在这里我们认为所有训练数据的
另外
关于期望  以互信息
以互信息
对于分类问题的EPE
先做一些符号约定:
分类问题的输出是离散型(随机)变量,定义其符号为贝叶斯分类器(Bayes classification):
我们通过
经过刚才的讲解,读者应该能较为清楚的感受到,统计学习中把
k近邻及其Majority
Vote选出类别的机制,本质上也是通过训练数据去近似
Bias-Variance Decomposition
先考虑在某个点
设训练集为
其中第一项是预测模型
注意这里算MSE拆分时的
对于线性回归模型
假设数据集
由于
可得到
并且在
维度灾难(Curse of Dimensionality)
待填坑
模型选择与误差(Model Selection and Bias)
参考文献
- 《统计学习方法》第二版 李航 ↩︎