一句话读论文:Map-view Transformer(CVPR2022)
一句话读论文:Cross-view Transformers for real-time Map-view Semantic Segmentation(CVPR 2022)
论文标题:Cross-view Transformers for real-time Map-view Semantic Segmentation(CVPR 2022)
论文地址:https://arxiv.org/abs/2205.02833
作者单位:The Chinese University of Hong Kong
代码地址:https://github.com/bradyz/ cross_view_transformers
一句话读论文:Our architecture implicitly learns a mapping from individual camera views into a canonical map-view representation using a camera-aware cross-view attention mechanism.
网络框架:
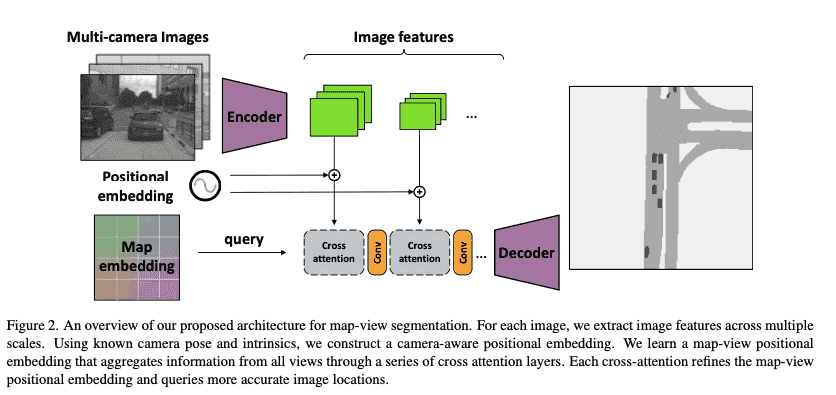
核心内容:
Motivation: 想做图像特征与地图特征的融合("model geometry and relationships between different view and a canonical map representation")
已有方法的问题:
- Image-based depth estimation are error-prone.
- Depth-based projections are a fairly inflexible and rigid bottleneck to map between views.
本文的思路:
是通过cross-view transoformer来做Map View 到Camera View的融合。相比于已有方法基于显式地几何关系地映射,这种融合的方式是一种隐式函数的映射("learn any geometric transformation implicitly and directly from data")。此外,transformer需要positional embedding来区分不同空间位置的特征。
注意力系数的计算方式比较巧妙:
几何意义:The uprojected image coordinate
for each image coordinate described a direction vector from the origin of camera to the image plane at depth 1. 代码实现:1)We encode this direction vector
using an MLP(shared across k views) into a D-dimensional positional embedding ... We combine this positional embedding with image features in the keys of our cross-view attention mechanism. 2)
从地图获得,没有高度信息怎么办:We start with a learned positional encoding . We build the map-view representation up over multiple iterations in our transformer... Each positional embedding is better able to project the map-view coordinates into a proxy of the 3D environment.
基于上述几何映射的注意力系数计算方式,论文做如下改动作为实际的计算方法:
实验结果:
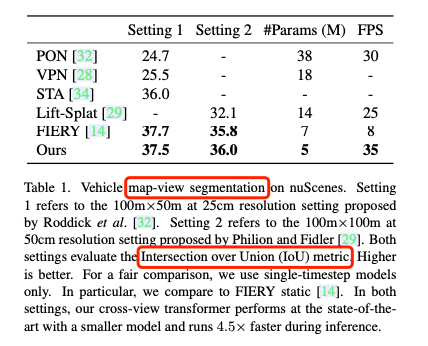
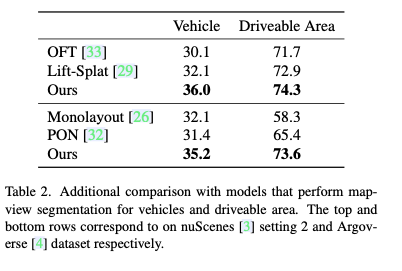


Related Work(可选):
你认为优点/不足/可以拓展改进的地方(可选):
优点:
- 利用了地图信息,这是一个比较有新意的setting.
- 提出的transformer不是简单的高维特征计算cos复杂度。从理论上来说,本文是巧妙利用三维点与二维相机视角存在的仿射变换的关系构建的计算方法。原始公式中只需要坐标信息 ,然后在此基础上拓展了图像和地图的positional embedding以及各自的特征信息(如transformer得到的特征向量,图像颜色,点云的极坐标信息等),可拓展性强。
不足:
- 本文中没有用到LiDAR点云数据。讲道理从LiDAR数据中可以直接获得准确的高度信息,为什么不用呢(是为了提高模型推理速度,避免使用点云数据?)。这样的话从地图中经过多层transformer来估计特征向量的方式总觉得有瑕疵。
- 实验评测在语义分割上做的,但是做的是俯视图语义分割而不是3D语义分割。实际应用中3D语义分割和2D图像语义分割比俯视图语义分割实用很多。俯视图语义分割的重要性有待商榷。此外实验结果虽然和传统方法comparable证明这种利用transformer的新技术路线是有用的,但是30多的mIoU和现在3D语义分割中78的mIoU相比仍然逊色很多。
可以拓展改进的地方:
- 后面利用这套同样的idea,去做一做3D语义分割或2D图像分割。这样能挖掘一个更有意思的课题,我从地图中学习到的信息对CameraView和3D点云分割能起到什么帮助?